An engineer editing a single line of code in an IDE consumes almost zero marginal server resources. But when an AI agent performs that same edit, it reads the surrounding files, compiles the codebase, executes a test suite, processes the stack trace, and feeds the updated logs back into its context window. Because LLM context processing grows quadratically with each turn, a single multi-step edit routinely consumes millions of tokens. This is the agentic loop multiplier: the mechanical reality that has rendered the traditional $20 flat-rate SaaS subscription completely unprofitable and economically non-viable.
To understand why flat-rate pricing fails, consider the physical limits of a GPU cluster. In a traditional SaaS model, a user pays $20 a month to access database servers that scale horizontally with minimal cost. If the user sits idle, the server costs nothing. If the user is active, their HTTP requests require negligible CPU cycles. In contrast, serving a frontier model like Claude 4 Sonnet or GPT-5 requires active memory bandwidth across multiple synchronized GPUs. Every token generated is a discrete matrix multiplication that cannot be cached or shared.
When an agent runs in an iterative loop—compiling, testing, and fixing—it triggers dozens of background inference calls. A professional developer utilizing an agentic IDE for four hours can easily run through $10 to $15 in raw compute costs.
The Quadratic Cost of Agentic Execution
This economic deficit triggered an industry-wide retreat from flat-rate billing. A viral thesis published by the development team behind Kilo Code on social media and detailed on the Kilo Code Blog predicted this structural collapse. By mid-2026, the prediction materialized. The industry's largest players systematically abandoned unlimited tiers, replacing them with metered credit pools, rigid quotas, and variable usage-based billing.
You might also like




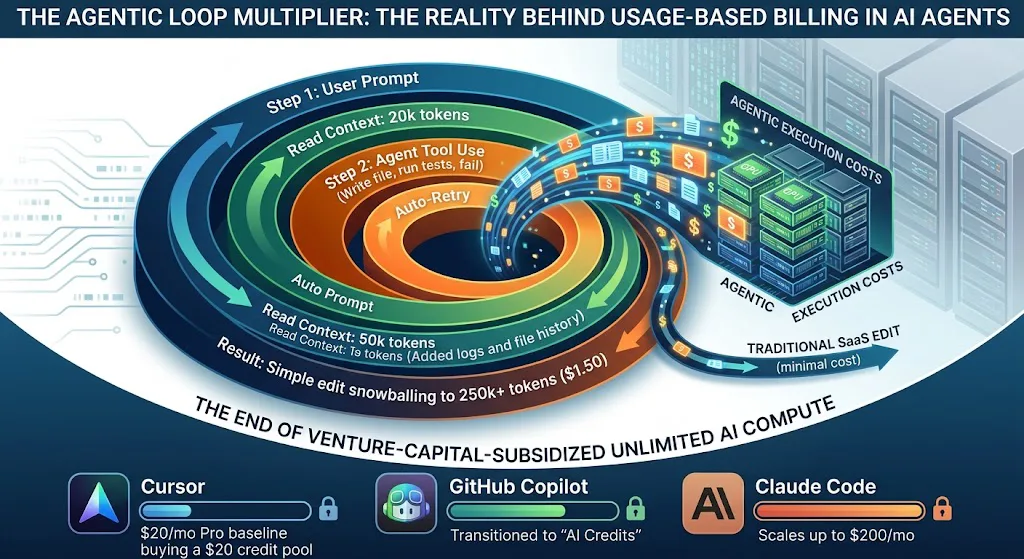
flowchart TD
subgraph THE INFERENCE SNOWBALL
A["Step 1: User Prompt"] -->|"Read Context: 20k tokens"| B["Step 2: Agent Tool Use<br/>(Write file, run tests, fail)"]
B --> C["Step 3: Auto-Retry"]
C -->|"Read Context: 50k tokens (Added logs and file history)"| D["Step 4: Resolve Fail"]
D -.-> E(["Result: Simple edit snowballing<br/>to 250k+ tokens ($1.50)"])
end
style E fill:#f9f2f4,stroke:#d9534f,stroke-width:2px
| Platform | Old Pricing Model | Current 2026 Pricing Structure | Overages & Limits |
|---|---|---|---|
| Cursor | $20/mo flat-rate with unlimited slow fallback. | $20/mo Pro baseline buying a $20 credit pool. | Additional requests draw down the credit pool or incur API-rate overages. |
| Cline / Roo Clinic | $15/mo flat-rate. | $20/mo Pro plan. | Shifted from credit roll-overs to rigid daily/weekly quota limits with a $200/mo Max tier. |
| GitHub Copilot | $10/mo flat-rate with unlimited premium requests. | $10/mo Pro plan transitioned to "AI Credits". | Agentic tasks draw down the credit pool directly based on token usage. |
| Claude Code | Direct API access. | Tiered quota system starting at $20/mo. | Scales up to $200/mo (Max 20x plan) for heavy repository workloads. |
The Mechanics of the Incentive Conflict
The shift to metered credit pools introduces a fundamental misalignment of incentives between platforms and developers. On a flat-rate plan, a platform's profit margin increases when users write less code or use weaker models. To protect their operating margins, closed-source subscription platforms enforce invisible rate limits, throttle execution speed during high-traffic windows, and silently route requests to cheaper, less capable models. This practice degrades the quality of agent output, turning a high-performing developer tool into a frustrating, unpredictable editor.
For the developer, this creates a high cognitive load. Rather than focusing on coding, users must continuously monitor their remaining credit balance, calculating whether a complex refactoring agent run will exhaust their monthly quota.
In contrast, using direct API keys or pay-as-you-go providers like Kilo Gateway makes the exact cost of each task quantifiable:
"A developer can run an agent, review the exact dollar cost of the generated pull request, and write it off as a direct operational expense. This makes it easier to mentally write off the low cost of wasted requests when the agent gets something wrong or spins its wheels, avoiding the financial anxiety of a dwindling monthly credit pool."
Enterprise BYOK and FinOps Optimization
This structural shift has also altered enterprise purchasing. The FinOps Foundation's 2026 State of FinOps Report identifies AI compute as the fastest-growing enterprise line item, with average corporate AI budgets climbing from $1.2 million in 2024 to $7 million in 2026. Because raw agentic cycles are highly volatile, enterprises are rejecting opaque subscription seats in favor of Bring-Your-Own-Key (BYOK) architectures.
Open-source platforms like Kilo Code allow engineering teams to connect their corporate API keys directly to the IDE, eliminating vendor markups, bypassing platform rate limits, and routing tasks to the most cost-efficient models dynamically. This approach ensures that teams pay exact wholesale provider rates with zero platform markup. On vacation, the team pays nothing; during a major release, they pay only for the exact compute consumed.
The broader macro-economic data confirms that the subsidies are ending. Despite generating massive revenues, major AI providers remain deeply unprofitable due to massive infrastructure spending. OpenAI continues to run at a loss, spending roughly $1.35 for every dollar it earns, largely driven by the daily cost of serving massive, un-metered inference requests. As capital markets demand a path to profitability, the era of venture-capital-subsidized "unlimited" AI compute has drawn to a close. Compute must be billed at its true utility cost.
flowchart TD
A["API KEY INTEGRATION"] --> B["Local Inference<br/>(Ollama/Qwen)"]
A --> C["Cloud API<br/>(Claude/GPT/Gemini)"]
B --> D["Dynamic Model Router<br/>(Optimized Routing)"]
C --> D
| Plan Metric | Subscription Agent (Cursor / Copilot) | BYOK Agent (Kilo Code / Cline + API) |
|---|---|---|
| Pricing Transparency | Opaque; hidden within proprietary credit conversions. | Transparent; billed per million tokens directly at provider rates. |
| Rate-Limiting | Vendor-enforced peak throttling and rolling windows. | None; limited only by the direct API provider tier. |
| Model Freedom | Restricted to vendor-approved frontier models. | Instant access to 500+ models, including custom local setups. |
| Cost Control | Zero visibility into per-request costs; unexpected billing overages. | High granular control; users can configure max context and model routing. |
Shifting From Technical to Financial Metrics
Optimizing code-generation cost now requires implementing programmatic model routing. Engineering organizations can no longer afford to default to flagship frontier models like Claude 4 Sonnet or GPT-5 for every minor IDE interaction.
A highly optimized team routes routine boilerplate, syntax checking, and localized refactoring to quantized local models (such as Qwen Coder or Llama 3.1 70B running on local hardware) or budget-tier cloud APIs. This preserves the expensive reasoning budgets of models like Claude Opus or OpenAI o1-pro exclusively for complex, multi-file architectural changes and automated debugging loops.
The teams that build these automated cost-guardrails and context controls directly into their development pipelines will maintain high output; those that rely on legacy flat-fee tools will find themselves throttled out of the market.







0 Comments
Log in to comment
Not a member yet? Join the community
Pick a meme
KlipyHave a great take?
Drop your email — we'll send a magic link so you can post it. No password.
Not a member of the community? Join today.
Join the community →