
Walk into any serious conversation about the future of artificial intelligence these days, and you’ll quickly hear the same refrain: data is the new oil. But unlike oil, this resource isn’t just finite—it’s actively degrading. Companies like OpenAI, Anthropic, Google, and Meta are consuming samples (the individual text snippets, images, code snippets, conversations, and labeled examples that fuel model training) at a scale that boggles the mind. We’re talking trillions of tokens per frontier model. And as they scramble to feed these digital beasts, the industry is confronting ballooning costs, privacy nightmares, and a contamination crisis that threatens to undermine the very progress they’re chasing.
I’ve spent time digging through financial reports, academic papers, lawsuits, and industry analyses from the past few years. What emerges isn’t a tidy success story of technological triumph. It’s a tale of insatiable hunger, creative (and sometimes questionable) sourcing tactics, mounting legal risks, and a feedback loop that some researchers warn could lead to models collapsing in on themselves. Let’s unpack it step by step.
The Insatiable Appetite for Samples
Modern large language models don’t learn from a few carefully chosen textbooks. They devour essentially the entire public internet—plus books, code repositories, scientific papers, forum discussions, and vast amounts of synthetic or human-curated data. Early models like GPT-3 trained on hundreds of billions of tokens. By GPT-4, estimates ran around 13 trillion. Meta’s Llama 3.1 405B reportedly used over 15 trillion tokens, much of it scraped from the web.
These “samples” aren’t abstract. They’re concrete instances: a Reddit thread, a news article, a captioned photo, a line of dialogue, or a labeled image for vision models. High-quality ones—diverse, factual, rich in rare edge cases—are especially prized because they help models generalize instead of merely memorizing patterns.
When readily available human-generated data began running short, companies turned to aggressive scraping, licensing deals, proprietary user data, and synthetic generation. Anthropic’s quietly notorious “Project Panama,” for instance, reportedly involved purchasing millions of physical books, slicing off their spines for high-speed scanning, and then destroying the remains to create clean training corpora free from digital noise. It “looked bad,” one report noted, which is why it stayed under wraps for so long.
The shift to synthetic data—AI-generated samples used to augment or replace human ones—seemed like an elegant workaround. But as we’ll see, it carries serious risks.
The Rising Cost of Data Aggregation
Feeding these models isn’t cheap. While the headline-grabbing numbers often center on compute (OpenAI reportedly spent billions on training runs, with projections climbing into the tens of billions annually in coming years), the data side is exploding too.
Licensing deals have become a seller’s market. OpenAI’s five-year agreement with News Corp was reportedly worth more than $250 million. Deals with Reddit hover around $60–70 million per year from both Google and OpenAI. Smaller but still significant arrangements with the Financial Times ($5–10 million annually), Axel Springer, Condé Nast, The Atlantic, and others add up to hundreds of millions across the industry.
Then there’s the specialized data market. Companies like Scale AI provide high-quality labeled samples and human feedback (RLHF data) critical for aligning models. Deals here range from OpenAI paying around $5 million to Meta shelling out $60 million in one reported tranche, with Scale itself paying a major tech firm $250 million for a large dataset. Analysts project the broader AI training data licensing market could hit $100 billion by 2030.
You might also like



These figures don’t capture everything. Internal data acquisition budgets at top labs reportedly run into the billions when including scraping infrastructure, annotation, synthetic data generation pipelines, and partnerships. One executive role was even floated with a $2.1 billion annual data spend. Add in the massive cloud commitments—Anthropic’s reported $200 billion over five years with Google Cloud—and the picture is clear: data aggregation has become a core strategic arms race, not an afterthought.
Yet many experts argue these licensed pockets, no matter how expensive, represent only a drop in the ocean compared to the trillions of tokens scraped from the open web. One analysis pointed out that it would take the New York Times hundreds of thousands of years to generate enough original text to train a single model like Llama 3 on its own. Licensing helps with quality and legal cover for specific corpora, but it doesn’t solve scale.
Privacy Concerns: Scraping the Human Web Has Consequences
All this data hunger runs straight into people’s private lives. Much of the training material comes from scraping websites, forums, social platforms, and public posts—often without explicit, informed consent. When that material includes personal information, medical details, faces, conversations, or biometric data, the ethical and legal problems multiply.
Lawsuits have piled up. The New York Times sued OpenAI and Microsoft over training on its articles. Authors, artists, and coders have filed class actions alleging copyright infringement and unauthorized use. Privacy-specific claims invoke laws like California’s CCPA, Illinois’ BIPA (for biometric data), and the EU’s GDPR. Clearview AI’s scraping of billions of faces for its facial recognition tool set a precedent with massive backlash and fines; similar scrutiny now hits AI labs.
GDPR is particularly strict: processing personal data for training generally requires a valid legal basis, transparency, and respect for data subject rights (access, deletion, correction). Many argue that indiscriminate scraping fails these tests. Stanford researchers found that major firms often use user chats for training by default, sometimes retaining data indefinitely, raising re-identification and memorization risks. Italy briefly banned ChatGPT over privacy worries, and regulators worldwide have issued warnings.
Even “public” data carries risks. Resumes with addresses, phone numbers, family details, and photos have ended up in massive scraped datasets. Models can sometimes regurgitate or infer sensitive attributes. The backlash has forced some changes—opt-outs, robots.txt respect (patchy at best), and tighter terms of service—but critics say it’s too little, too late. Individuals rarely control whether their old forum posts, blog entries, or photos train the next GPT or Claude.
The Contamination Crisis: When Samples Go Bad
This brings us to the most critical issue: sample contamination. It comes in two overlapping flavors, both worsening over time.
Benchmark Contamination first. Public evaluation sets like MMLU, GSM8K, or HumanEval have lived on the internet for years—in papers, forums, GitHub repos, and discussions. When training corpora swallow them (as web scrapes inevitably do), models can memorize rather than truly learn. Performance scores become inflated; what looks like breakthrough reasoning is sometimes just regurgitation. Studies have found contamination rates from 10–50% or higher on popular benchmarks, with larger models and more recent training runs showing worse leakage. Detection is imperfect, especially for closed models, and the problem grows as benchmarks age and models scale. Researchers now guard new tests jealously or use private held-out sets.
The far more existential threat is synthetic data contamination and model collapse. As generative AI proliferates, the web is flooding with AI-generated text, images, and video—“AI slop.” Estimates suggest 15–50% of web text may already be AI-influenced or generated; one 2025 Ahrefs study found 74.2% of new webpages contained AI-generated material. Some projections put the figure approaching 90% in coming years. This is exponential growth, driven by the ease of producing content at scale.
When the next generation of models trains on this polluted pool, problems compound. The landmark 2024 Nature paper by Shumailov, Shumaylov, and colleagues demonstrated “model collapse”: recursive training on synthetic data causes progressive degradation. Rare events and long-tail knowledge disappear first (the model “forgets” the red hats in favor of the common blue ones). Outputs grow homogenized, bland, error-prone, or outright gibberish. Visualizations from related experiments show handwritten digits devolving from clear numbers into blurry, meaningless shapes after 20–30 generations of synthetic training.
It’s like the telephone game played across the entire internet, or repeatedly photocopying a photocopy until only noise remains. Entropy drops. Variance collapses. One analysis warned that even small percentages of synthetic data can trigger it, and once the internet becomes mostly AI-derived, cleaning it becomes nearly impossible. Epoch AI and others predict high-quality human text could be effectively exhausted between 2026 and 2032. Without fresh, diverse real-world samples, progress stalls—or worse, reverses.
The exponent increase is measurable: pre-ChatGPT, AI-generated content was negligible. Post-2022, it exploded. Content farms pivoted overnight. Search results and training crawls now ingest more machine output than ever. Retrieval-augmented systems are already struggling with polluted evidence. This isn’t a distant theoretical risk; it’s happening in real time.
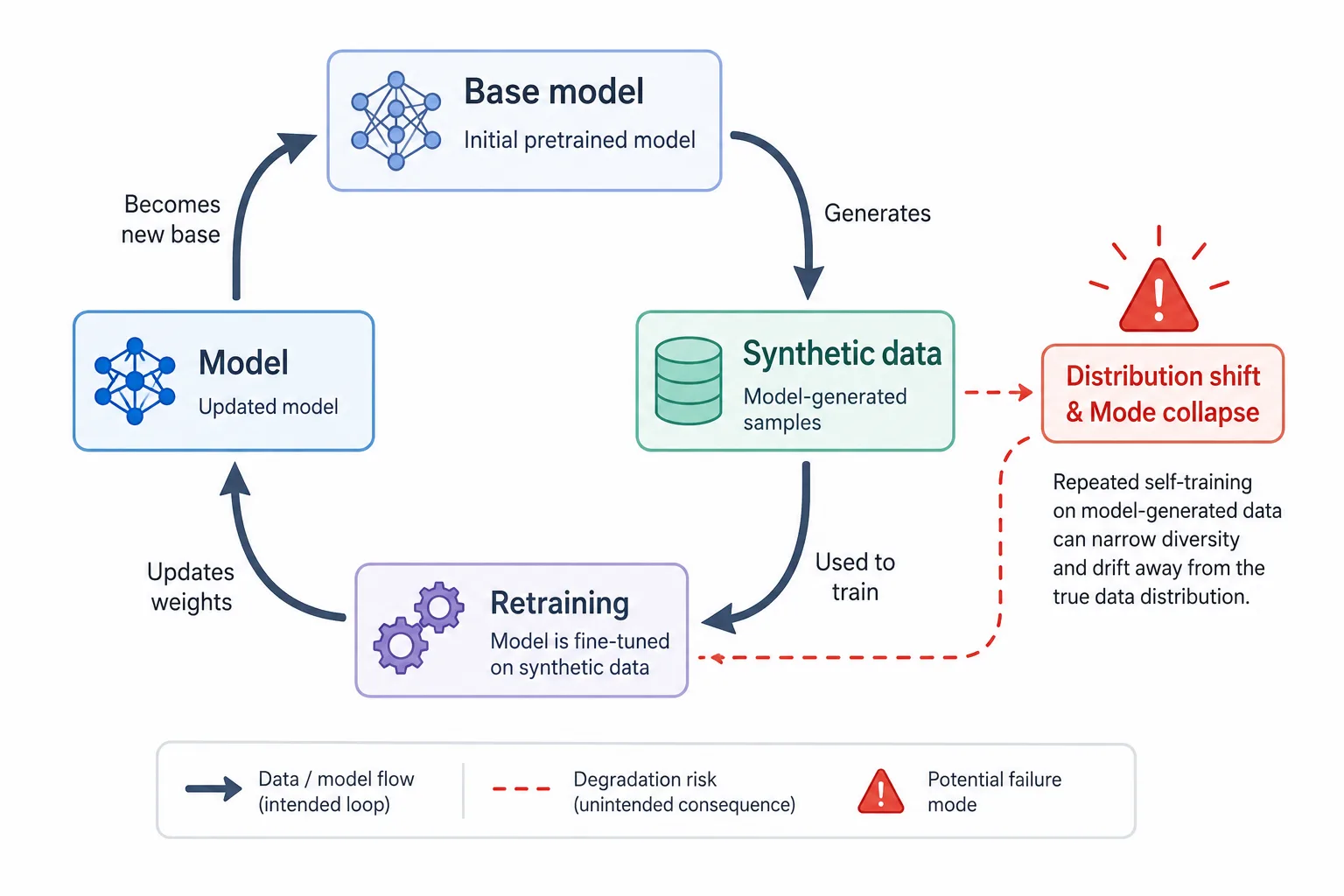
(Example of model collapse in visual data)
Looking Ahead: Can We Escape the Ouroboros?
The industry isn’t blind to this. Approaches include heavier curation, accumulating real human data alongside synthetic (which some papers suggest can bound the collapse), better detection and filtering of AI-generated content, private datasets, physical media, and even “data dignity” or compensation schemes. Startups are emerging around high-quality human feedback and novel curation methods. Regulatory pressure—on privacy, copyright, and transparency—may force cleaner practices, though it could also slow innovation.
Yet the fundamental tension remains. Frontier models demand ever-larger, higher-quality samples at a time when the global data ecosystem is both exhausting its best sources and contaminating itself. Licensing buys time and legal breathing room for big publishers, but it can’t replicate the messy diversity of the open web. Synthetic data scales, but it risks turning models into echoes of echoes.
We’ve built astonishingly capable systems by feeding them the collective output of humanity. The question now is whether we can keep them vital—or whether the snake will finish swallowing its own tail. The coming years of AI development will be defined as much by how creatively (and responsibly) we source and protect training samples as by any algorithmic breakthrough.
The data hunger isn’t going away. How we satisfy it—without poisoning the well—will shape whether the next wave of AI truly advances understanding or simply recycles diminishing returns.
- This article draws on reporting from Quartz, ProMarket, Nature, arXiv papers, Epoch AI trends, WSJ, Washington Post investigations, Stanford studies, and multiple academic surveys on contamination and privacy (2023–2026). Figures are estimates where exact disclosures are unavailable, as is common in this secretive field



0 Comments
Log in to comment
Not a member yet? Join the community
Pick a meme
KlipyHave a great take?
Drop your email — we'll send a magic link so you can post it. No password.
Not a member of the community? Join today.
Join the community →